1. What is an operating system?
An operating system is a program that controls the execution of application programs and acts as an interface between the user of the computer and the computer hardware. It creates a user friendly environment. We can view an operating system as a resource allocator.
2. What are the two primary goals for operating system?
3. Define resource allocator?
OS as a resource allocator keeps track of the status of each resources and decides how to allocate them to specific programs and users. so that it can operate the computer system efficiently and fairly.
4. What are the advantages of multi processor system (or) tightly coupled system?
Interrupted process state (i.e) increased reliability.
5. Define graceful degradation and fault tolerance?
The ability to continue providing service proportional to the level of surviving hardware is called graceful degradation. Systems designed for graceful degradation are also called as fault tolerance.
6. Differentiate symmetric and asymmetric multi processing?
SYMMETRIC |
ASYMMETRIC |
|
|
7. Define loosely coupled system (or) distributed system?
The computer networks used in the applications consist of a collection of processors that do not share memory or a clock. Instead, each processor has its own local memory. The processors communicate with one another through various communication lines such as high speed bus or telephone lines, these systems are usually referred as loosely coupled system or distributed system
8. Define clustered system?
Clustered systems gather together multiple CPU’s to accomplish computational work. They are composed of two or more individual system coupled together. Clustered computers share storage and are closely linked via LAN networking. Clustering is usually performed to provide high availability.
9. Differentiate symmetric and asymmetric clustering?
SYMMETRIC |
|
Applications and they are monitoring each other.
does require more than one application be available to run. |
|
10. What is real time system? Mention its types?
A real time system is one that must react to inputs and responds to them quickly. A real time system cannot afford to be late with a response to an event.
TYPES:
11. Define web clipping.
One approach for displaying the content in web pages is web clipping, where only a small subset of a web page is delivered and displayed on the handheld device.
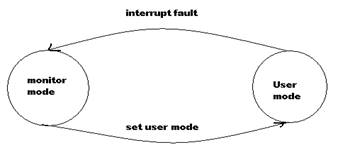
12. What is dual mode operation?
Dual mode operation provides the protection to the OS from unauthorized users. In dual mode operation two separate modes are used for working of OS.
13. How do you ensure memory protection?
We can provide the memory protection by using two register usually a base register which holds the smallest legal physical memory address and a limit register which contains the size of the range.
14. Mention Operating system component activities.
15. What is command interpreter?
Command interpreter acts as an interface between the users and the OS. Many commands are given to the operating system by control statements. Its function is: to get the next command statement and execute it. It is also called Control-card interpreter or the command-line interpreter. Some OS include the command interpreter in the kernel. Other Os like MS-DOS and UNIX treat the command interpreter as a special program.
16. What are the services provided by operating system?
17. Define system calls. Give examples.
System calls provide the interface between a process and OS. These calls are generally available as assembly language instructions. A system call instruction is an instruction that generates an interrupt that cause the OS to gain control of the processor.
Eg.fork, exec, getpid, wait.
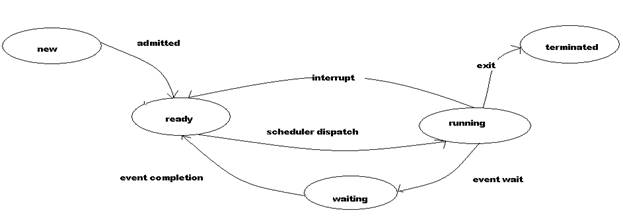
18. Draw the process state diagram.
19. What is process control block? Give its diagram.
Each process contains the process control block. PCB is a data structure used by the OS. OS groups all information that needs about particular process.
Pointer |
process state |
Process number |
|
Program counter |
|
Registers |
|
Memory limits |
|
List of open files |
|
20. What are the multithreading models in OS?
21. Define long term and short term scheduler.
It determines which programs are admitted to the system for processing. It selects from the queue and loads the processes into memory for the CPU scheduler.
When process changes the state from new to ready then there be long term scheduler.
It is the change of ready state to running state of the process also known as dispatcher, execute most frequently and makes the fine grained decision of which process to execute next.
22. What is context switch?
When the scheduler switches the CPU from executing one process to executing another, the context switcher saves the content of all processor registers for the process being removed from the CPU in its process descriptor.
23. What is cascading termination?
If a process terminates, then all its children must also be terminated. This phenomenon, referred to as cascading termination.
24. What are the advantages of co-operating process?
25. Give the advantages of Layered approach.
The main advantage of the layered approach is modualarity.The layers are selected such that each uses functions and services of only lower-level layers. This approach simplifies debugging and system verification.
26. Define microkernel.
The microkernel method structures the OS by removing all nonessential components from the kernel, and implementing them as system and user-level programs. The result is a smaller kernel. Microkernel provide minimal process and memory management in addition to a communication facility.
27. What is virtual machine?
The system programs are at a level higher than that of the other routines, the application programs may view everything under them in the hierarchy. This layered approach is taken to its logical conclusion in the concept of a virtual machine. The virtual machine approach, each process is provided with a copy of the underlying computer.
Eg.The VM operating system for IBM systems.
28. What are the benefits of virtual machine?
29. Define JVM.
JVM is a specification for abstract computer.
Java Virtual Machine (JVM) is a combination of class loader, a class verifier, and java interpreter.
The JVM makes it possible to develop programs that are architecture neutral and portable. The implementation is specific for each system and it abstracts the system in a standard way to a java program, providing the architecture neutral interface.
30. What is Socket? What are the three different types of sockets provided by Java?
Socket is an end point of communication. It is a combination of IP and port number.
TYPES:
31. Define RPC and RMI.
Remote Procedure Call (RPC) allows IPC by providing a communication mechanism similar to ordinary function or procedure calls. RPC servers are multithreaded. RPC system using a separate Stub for each remote procedure.
Remote Method Invocation (RMI) is one of the special features of java. RMI using a stub at client side and a skeleton at server side. RMI allows a thread to invoke a method on a remote object.
32. What is Thread? Mention the benefits of Multithreaded Programming.
A thread is a flow of execution through the process code, with its own program counter, system register and stack. It is a light weight process.
BENEFITS:
33. Define user and kernel thread.
User threads are supported above the kernel and are implemented library at the user level. The library provides support for thread creation, scheduling, and management with no support from the kernel.
Kernel threads are supported directly by the operating system: the kernel performs thread creation, scheduling, and management in kernel space
34. Define Target thread and Thread Cancellation.
35. What are the two different scenarios for thread cancellation?
36. Explain signal handling.
Signals are used in UNIX systems to notify a process that a particular event has occurred. A signal may be received either synchronously or asynchronously, depending upon the source and the reason for the event being signaled. Whether a signal is synchronous or asynchronous, all signals follow the same pattern:
37. What is APC?
Asynchronous procedure calls (APC) facility allows a user thread to specify a function that is to be called when the user thread receives notification of a particular event.
38. Define Thread pools.
The general idea is to create a number of threads at process startup and place them into a pool. When a server receives a request, it awakens a thread from this pool if one is available passing it the request to service. Once the thread completes its service, it returns to the pool awaiting more work. If the pool contains no available thread, the server waits until one becomes free.
39. Write any four issues to consider with multithreaded programs.
40. Differentiate the loosely coupled system and tightly coupled system.
Loosely coupled system |
Tightly coupled system |
|
|
41. Define cache coherency.
In multiprocessor environment, a copy of data may exist simultaneously in several caches. Since the various CPUs can all execute concurrently, we must make sure that an update to the data in one cache is immediately reflected in all other caches. This situation is called cache coherency.
42. Compare the process and threads.
Process |
Threads |
Process.
With OS.
Kernel. |
Process.
Call an OS.
|
43. Mention the benefits of thread pools.
16 Mark Questions
1. a) Explain in detail of the services provided by an operating systems.(Pg.no 16)
b) Why protection is necessary in an operating systems. (Pg.no:42)
2. a) Discuss the features of the real-time systems. (Pg.no.17)
b) Compare batch and time sharing operating systems.( Pg.no.7)
3. a) Explain the Inter Process Communications (IPC) with an example.
(Pg.no.109)
b)Write short notes on deadlock recovery. (Pg.no.264)
4. a)Explain direct and indirect communication in IPC.( Pg.no.111)
b)Discuss briefly about thread. (Pg.no.129)
5. Explain the system components of operating systems. (Pg.no.55)
6. Write short notes on
a) virtual machine (Pg.no.63) b) system calls (Pg.no.80)
7. Explain the following. (Pg.no.12)
(i)Multiprocessor system (ii) Distributed system
(iii) Clustered system (iv) Real time system.
8. Discuss about Communication in client server systems with neat diagram
(Pg.no.117)
Unit II - Process Scheduling and Synchronization
2 Marks
1) What is long term and short term schedulers?
CPU is called as a Short term scheduler. Whenever the CPU becomes idle, the operating system must select one of the processes in the ready queue to be executed. The selection process is carried out by the short-term scheduler or CPU scheduler.
Long term scheduler or job scheduler selects the process in job queue and put into the ready queue for CPU execution.
2) Define the shortest remaining time first scheduling.
Preemptive SJF scheduling is sometimes called Shortest-remaining-time-first scheduling. The choice arises when a new process arrives at the ready queue while a previous process is executing. The new process may have a shorter next CPU burst than what is left of currently executing process. A preemptive SJF algorithm will preempt the currently executing process.
3) Differentiate between preemptive and non-preemptive?
Preemptive Scheduling: 1. when process switches from running State to ready state.
2. When a process switches from waiting state to ready state.
Non preemptive scheduling: once the CPU has been allocated to a process, the processkeeps the CPU until it releases the CPU either by a process switches from running state to waiting state or the process terminates.
4) Define dispatcher and dispatch latency.
The dispatcher is the module that gives control of the CPU to the process selected by short term scheduler. The function involves:
Dispatch latency: Time taken by the dispatcher to stop one process and start another process for running is known as the dispatch latency.
5) Define throughput and response time?
Throughput refers to the no of process completed per time unit. Higher the throughput higher amount of work can be done by the CPU.
Response time refers to the measure the amount of time taken from submission of the request till the first response is found.
6) Define turnaround time and waiting time.
Turnaround time is the interval from the time of submission of a process to the time of completion. Turnaround time is the sum of periods spent waiting to get into the ready queue , executing on the CPU and doing I/O.
Waiting time is the average period of time a process spends waiting in the ready queue.
7) What is starvation or indefinite blocking?
The process that is ready to run but lacking the CPU can be considered as starvation or indefinite blocking.
8) Define aging.
A solution to the problem of the indefinite blocking or starvation is aging. Aging is a technique of gradually increasing the priority of processes that wait in the system for a long time.
9) Define priority inversion.
The situation in which the higher priority process would be waiting for the lower priority process to complete is called as priority inversion. This can solved via priority–inheritance protocol.
10) What is critical section and race condition?
Critical section is a segment of code in which the process may be changing common variables, updating table, writing a file etc. When one process is executing in critical section no other process is allowed to be executed in its critical section.
A situation in which several processes access and manipulate the same data concurrently and the outcome of the execution depends upon on the particular order of the execution is called as race condition.
11) What are requirements to be satisfied by the critical section problem?
The 3 conditions to be satisfied are
12) Define bakery algorithm.
Bakery algorithm is used to solve the critical section problem for n process. The bakery algorithm was developed for a distributed environment, which permits processes to enter into the critical section in the order of the token numbers.
13) Define semaphore?
Semaphore is used to solve critical section problem. A semaphore is a synchronization tool. Semaphore is a variable that has an integer value upon which the following operations are defined:
1) Wait
2) Signal
There are two types of semaphore 1. Counting semaphore 2. Binary semaphore.
14) What is busy waiting and spin lock?
While a process is in its critical section, any process that tries to enter its critical section must loop continuously in the entry code. This continual looping is called busy waiting. Busy waiting wastes CPU cycles that some other process might be able to use productively. This type of semaphore is also called a spinlock.
15) Define binary semaphore
Binary semaphore is a semaphore with an integer value that can range only between 0 and 1.
16) What is real time scheduling? What are its types?
A real-time system is used when rigid time requirements have been placed on the operation of a processor or the flow of data. There are two types of real time scheduling
17) Define preemption points.
Preemption points are one of the ways to keep the dispatch latency low. Preemption points are usually used to see whether a high priority process needs to be run.
18) What is the use of queueing model?
Queueing analysis can be useful in comparing scheduling algorithms, but it also has limitations. If the system is in ready state, then the number of process leaving the queue must be equal to number of process that arrive, thus
ή=λ*w
The above equation is called little’s formula.
19) What are the various operation used in semaphores?
The two operations that are used in semaphores are
20) Define monitors.
Monitor is a programming language construct that provides equivalent functionality to that of the semaphores but it is easier to control. A monitor is characterized by a set of programmer-defined operators. Monitors are a high level data abstraction tool combining three features:
Shared data
Operation on data
Synchronization, scheduling
21) Define sleeping barber problem?
A barbershop consisting of a waiting room with n chairs and the barber room containing the barber chair. If there are no customers to be served, the barber goes to sleep. If a customer enters the barbershop and all chair are occupied, then the customer leaves the shop. If the barber is busy but chairs are available, then the customers sits in one of the free chairs. If the barber is a sleep, the customer wakes up the barber.
22) Define cigarette-smokers problem.
There are three smoker process and one agent process. Each smoker continuously rolls a cigarette and then smokes it. But to roll and smoke a cigarette, the smoker needs three ingredients: tobacco, paper and matches. One of the smoker processes has paper, another has tobacco and the third has matches. The agent places two of the ingredients on the table. The smoker who has the remaining ingredients then makes and smokes a cigarette, signaling the agent on completion. The agent then puts out of the three ingredients and the cycle repeats. This is called cigarette-smokers problem.
23) What is the necessary condition for deadlock?
A deadlock situation can arise if the following four conditions hold simultaneously in system:
24) What is resource allocation graph?
Dead locks can be described more precisely in terms of directed graph called a system resource-allocation graph. This graph consists of set of vertices V and set of edges E. Refer fig 8.1 (pg no 247)
25) What are the data structures required for the bankers algorithms?
The data structures used for bankers algorithm are
26) How do you recover the system from deadlock?
There are generally two methods to recover from deadlock
27) How do you select a victim for resource preemption?
28) What are the methods for handling the deadlock?
29) How do you avoid deadlock?
System must always in safe state.
Resource allocation graph should not consist of cycle.
System must satisfy the safety and resource-request algorithm.
16 Mark Questions
(i)FIFO (ii)SJF (iii)SRT(preemptive SJF) (iv)RR
(i)First fit (ii)Best fit (iii)Worst fit
Unit III – Storage Management
2 Marks
Logical Address Space |
Physical Address Space |
Logical address is generated by CPU. |
Physical Address is an address of main memory. |
Set of all logical addresses generated by program is a Logical Address Space. |
Set of all physical addresses corresponding to logical address is a Physical Address Space. |
2. Define Overlays.
The idea to keep in memory only those instructions and data that are needed at any given time are known as overlays. We can use overlays to enable a process to be larger than the amount of memory allocated to it.
3. Define Swapping.
It is a technique of temporarily removing inactive program from the memory of a system. It removes the process from the primary memory when it is blocked and deallocating the memory. Then this free memory is allocated to other processes.
4. What is fragmentation?
fragmentation is a phenomenon in which storage space is used inefficiently, reducing storage capacity and in most cases performance. The term is also used to denote the wasted space itself.
There are three different but related forms of fragmentation: external fragmentation, internal fragmentation, and data fragmentation
5. What are the 2 types of fragmentation?
The 2 types of fragmentations are,
6. Define Compaction.
When enough total memory space exists to satisfy a request, but it is not contiguous, storage is fragmented into a large number of small holes. This situation leads to the external fragmentation. One of the solutions to this problem is compaction. Compaction is to move all the allocated holes to one side and all free holes are moved to another side.
7. What is paging?
Paging is a memory management scheme that permits the physical address space of a process to be non-contiguous. Paging reduces the external fragmentation.
8. What are the advantages of Paging?
9. What is TLB?
The TLB is associative, high speed memory. Each entry in the Translation Look aside Buffer (TLB) consists of two parts: a key or tag and a value. The search is fast, hardware is expensive. The number of entries in a TLB is small, often numbering between 64 and 1,024.
10. Define hit ratio.
The percentage times that a particular page number is found in the TLB is called the hit ratio.
11. How do you calculate the effective memory access time?
To find effective memory access time, we must weigh each by its probability:
For example, consider a page number that is found 80 percent of times in a TLB.
If it takes 20 nanoseconds to search and 100 nanoseconds to access the memory, then the mapped memory access takes 120 nanoseconds. If we fails to find page number in TLB (20 nanoseconds), then we must first access memory for the page table and frame number (100 nanoseconds), and then access the desired byte in memory (100 nanoseconds), for a total of 220 nanoseconds.
Effective memory access time = 0.80*120+0.20*220
= 140 nanoseconds.
12. Define reentrant code or pure code.
Re-entrant code is non-self-modifying code. If the code is re-entrant, then it never changes during execution.
13. Define segmentation.
Segmentation is a memory management scheme. Segmentation divides a program into a number of smaller blocks called segments. A segment can be defined as a logical grouping of information, such as sub routine, array or data area. Segmentation is variable size.
14. Differentiate LDT and GDT.
Local Descriptor Table |
Global Descriptor Table |
Information about the first partition among the two partitions of the logical address space is kept in the LDT. |
Information about the second partition among the two partitions of the logical address space is kept in the GDT. |
This first process is private to the processes. |
This second process is shared among to the processes. |
15. What is address binding?
Binding the memory address of instructions and data is called as address binding. Address binding can be done in three ways
16. How do you protect the memory?
By implementing the machine architecture in the form of memory bound registers we can protect the memory. By using Memory management Unit that is combination of relocation register and limit register we protect the memory.
17. What is TLB hit & TLB miss?
The required page is available in the TLB cache, and then it is called TLB hit. The required page is not in the TLB, it is called TLB miss.
Refer the page number: 293
18. What are the different types of page table structure?
19. Give 2 examples of OS for segmentation with paging.
20. Define Virtual memory.
Virtual memory is a technique that allows the execution of processes that may not be completely in memory. One major advantage of this scheme is that programs can be larger than physical memory. Running a program that is not entirely in memory would benefit both the system and the user. Virtual memory is commonly implemented by demand paging. Virtual memory is available in the secondary storage.
21. Define demand paging.
Virtual memory is commonly implemented by demand paging. A demand paging is similar to a paging system with swapping. With demand paging, a page is brought into the main memory only when a reference is made to a location on that page.
22. What is lazy swapper or pager?
Lazy swapper is a concept used in demand paging. A swapper manipulates entire processes, whereas a pager is concerned with the individual pages of a process. We thus use pager, rather than swapper, in connection with demand paging.
23. What is pure demand paging?
When the operating system sets the instruction pointer to the first instruction of the process, which is on a non-memory-resident page, the process immediately faults for a page. After this page is bought into memory, the process continues to execute, faulting as necessary until every page that it needs is in memory. At that point, it can execute with no more faults. This scheme is called pure demand paging: Never bringing a page into memory until it is required.
24. Explain equal allocation & proportional allocation.
The easiest way to spilt m frames among n processes is to give everyone an equal share, m/n frames. This scheme is called equal allocation.
We allocate available memory to each process according to its size. This scheme is called proportional allocation.
25. What is dirty bit or modified bit?
If no frames are free, two page transfers are required which doubles the page fault service time and increases the effective access time accordingly. We can reduce this over head by using modify bit or dirty bit. Each page or frame may have a modify bit associated with it in the hardware. The modify bit for a page is set by the hardware whenever any word or byte in the page is written into, indicating that the page has been modified.
26. What is the major problem for implementing demand paging?
- It needs some hardware and software support
- the major difficulty occurs when one instruction may modify several different locations.
27. Define Belady’s Anomaly.
For some page replacement algorithms, the page fault rate may increase as the number of allocated frames increases. This problem is known as Belady’s Anomaly. FIFO page replacement algorithm may affect this unexpected problem.
28. What is the difference between global and local replacement algorithm?
Global replacement allows a process to select a replacement frame from the set of all frames, even if that frame is currently allocated to some other process; one process can take a frame from another.
Local replacement requires that each process select from only its own set of allocated frames.
29. Define Thrashing.
The high paging activity is called Thrashing. A process is thrashing if it is spending more time paging than executing.
30. How do you calculate the effective memory access time?
Effective access time is directly proportional to the page fault rate. It is important to keep the page fault rate low in a demand paging system. Otherwise, the effective access time increases, slowing process execution dramatically.
Let p be the probability of a page fault (0≤p≤1)
Effective access time = (1-p)*ma + p*page fault time
Where
p – Page fault
ma – memory access time
31. Define zero-fill-on-demand.
Many operating systems provide a pool of free pages for new requests. These free pages are typically allocated when the stack or heap for a process must expand or for managing copy-on-write pages. These pages are allocated by operating system using a technique called zero-fill-on-demand. Zero-fill-on-demand pages have been zeroed-out before being allocated, thus erasing the previous contents of the page.
32. What is copy-on-write?
Copy-on-write works by allowing the parent and child processes to initially share the same pages. These shared pages are marked as copy-on-write pages, meaning that if either process writes to a shared page, a copy of the shared page is created.
33. What is the cause of thrashing?
1. Thrashing results in severe performance problems.
2. CPU utilization is too low.
3. Page fault rate may increases.
4. Reduce the system throughput.
34. Difference between segmentation & paging.
segmentation |
paging |
Program is divided into variable size segments. |
Program is divided into fixed size pages. |
It is slower than paging. |
It is faster than segmentation. |
Segmentation is user view of memory. |
Paging is not a user view of memory. |
Segmentation may suffer from external fragmentation. |
Paging suffers from internal fragmentation. |
It uses segment table as a hardware support |
It uses page table as a hardware support |
It does not use TLB |
It use the TLB cache |
35. Compare paging with demand paging.
paging |
Demand paging |
Program is divided into fixed size pages. |
Program is divided into fixed size pages. |
It is faster |
It is some what slow compare to paging . |
Whole program is loaded into main memory when it is executed |
Only needed page should loaded into memory |
It does not use the page replacement algorithm |
It uses the page replacement algorithm |
It can not affected by the thrashing |
It may affected by the thrashing |
Effective access time is less |
Effective memory access time is high compare to paging |
36. When does page fault occurs?
The required page is not available in main memory, and then the page fault will occur.
16 Mark Questions
Unit IV – File Systems
2 Marks
1.Mention different file attributes.
i) Name
ii)Identifier
iii)Type
iv)Location
v)Size
vi)Protection
vii)Time,date,and user identification
2. Mention different file operations.
` i) Creating a file
ii) Writing a file
iii) Reading a file
iv) Repositioning within a file
v) Deleting a file
vi) Truncating a file
3. Define consistency semantics
4. Define immutable shared files.
5. How do you give the protection for files?
Protection can be provided in many ways.
6. Define packing.
All disk I/O is performed in units of one block(physical record), and all blocks are same size. It is unlikely that the physical record size will exactly match the length of the desired logical record. Logical records may even vary in length. Packing a number of logical records into physical blocks is a common solution to this problem.
7.Compare sequential and direct access.
Sequential access |
Direct access |
Information in the file is processed in order, one record after the other. |
A file is made up of fixed –length logical records that allow programs to read and write records rapidly in no particular order. |
Sequential access is based on a tape model of a file, and works as well on sequential access devices as it does on random-access ones. |
The direct access method is based on a disk model of a file, since disks allow random access to any file block. |
A read operation reads the next portion of the file and automatically advances a file pointer which tracks the I/O location. Similarly, a write appends to the end of the file and advances to the end of the newly a written material. |
We have read n, where n is the block number, rather than read next, and write n rather than write next. |
Files are belongs to this type |
Databases are often of this type. |
8.What are the operations performed in the directory?
9.Differentiate the absolute path name and relative path name.
Absolute path name |
Relative path name |
An absolute path name begins at the root and follows a path down to the specified file, giving the directory names on the path |
A relative path name defines a path from the current directory. |
Example: C:\programfiles\windows\os\test.doc |
Ex: \os\test.doc |
10.Define garbage collection.
11. Define cluster.
A disadvantage to linked allocation is the space required for the pointers. The usual solution to this problem is to collect blocks into multiples, called clusters, and to allocate the clusters rather than blocks.
12. What is the classification of users in connection with each file?
Owner: the user who created the file is the owner.
Group: A set of users who are sharing the file and need similar access is a group, or work group.
Universe: All other users in the system constitute the universe.
13. Define anonymous access in FTP.
14. What is the disadvantage of two level directory structures?
The two level directory structures effectively isolate one user from another. This isolation is an advantage when the users are completely independent, but is a disadvantage when the users want to cooperate on some task and to access one another’s files. Some systems simply do not allow local user files to be accessed by other users.
15. Draw the diagram for layered file system.
Application programs
![]()
Logical file system
![]()
![]() File -organization module
File -organization module
![]() Basic file system
Basic file system
![]() I/O control
I/O control
Devices
16. Define i) Boot control block ii) Partitioned control block
i)
ii)
17.Define RAW disk.
18.Mention two important function of VFS.
Virtual File System serves two important functions as follows
1.It separates file-system-generic operations from their implementation by defining a clean VFS interface. Several implementations for the VFS interface may coexist on the same machine, allowing transparent access to different types of file systems mounted locally.
2.The VFS is based on a file-representation structure, called a vnode, that contains a numerical designator for a network-wide unique file.(UNIX inodes are unique within only a single file system).This network-wide uniqueness is required for support of network file systems. The kernel maintains one vnode structure for each active node(file or directory).
19.What are the ways we implement the directory?
1.Linear list
2.Hash table
20. What is FAT?
21. How do you manage the free space?
22.What is the job of consistency checker?
The consistency checker compares the data in the directory structure with the data blocks on disk, and tries to fix any inconsistencies it finds.
23.Define Journaling or Log-based transaction-oriented.
Frequently in computer science, algorithms and technologies transition from their original use to other applicable areas. Log-based-recovery algorithms are mainly used in database. These logging algorithms have been applied successfully to the problem of consistency checking. The resulting implementations are known as Log-based transaction-oriented (or Journaling) file systems.
24 What are synchronous writes and asynchronous writes?
Synchronous writes occur in the order in which the disk subsystem receives them, and the writes are not buffered. Thus calling routine must wait for the data to reach the disk drive before it can proceed.
Asynchronous writes are done the majority of the time. In an asynchronous write the data is stored in the cache and returns control to the caller.
25.What are difference between the RAM disk and disk cache?
RAM disk |
Disk cache |
A section of memory is set aside and treated as a RAM disk or Virtual disk. |
Some systems maintain a separate section of memory for a disk cache, where blocks are kept under the assumption that they will be used again shortly. |
The contents of the RAM disk are totally user controlled. |
The disk caches are under the control of the operating system. |
26. What is page cache?
The page cache uses virtual-memory techniques to cache the file data as pages rather than as file-system-oriented blocks. Caching file data using virtual addresses is far more efficient than caching through physical disk blocks.
27.Define Double caching.
Double caching requires caching file-system data twice. First, reading file-system from the disk block and storing them in the buffer cache. Second, the contents of the file in the buffer cache must be copied into the page cache.
28.What are the advantages of Linked allocation and Indexed allocation?
Advantages of Linked allocation: It solves the external-fragmentation and size-declaration problems of contiguous allocation. Advantages of Indexed allocation: It supports the efficient direct access methods over the disk. It also solves the external-fragmentation and size-declaration problems of contiguous allocation.
16 Mark Questions
Unit V – I/O Systems
2 Marks
The reliability of a hard disk drive is typically described in terms of a quantity called Mean Time Between Failures (MTBF). MTBF is actually measured in drive-hours per failure.
It enables the computer to change the removable cartridge in a tape or disk drive without human assistance.
MAJOR USES:
Backups
Hierarchal storage systems
A Variety of disk organization techniques collectively called Redundant Arrays of Inexpensive Disks (RAID). RAID is commonly used to address the performance and reliability issues of the storage medium. Now, I in RAID stands for “independent”, instead of “inexpensive”.
The main goal of swap space is to provide best throughput for virtual memory system.
Streams enable an application to assemble pipelines of driver code dynamically. It is a full duplex connection between a device driver and a user level process. STREAM consists of a stream head, stream modules and driver end.
It provides a frame work to a modular and incremental approach to writing device drivers and network protocols.
Before a disk can store data, it must be divided into sectors that the disk controller can read and write. This process is called low-level formatting. Low level formatting is defined as that fills the disk with a special data structure for each sector. It is also known as Physical Formatting.
Low level formatting is defined as that fills the disk with a special data structure for each sector. The data structure for sector consists of a header, data area and a trailer. The header and trailer contain information used by the disk controller, such as a sector number and an ECC. When the controller writes a sector of data during normal I/O, the ECC (Error Correcting Code) is updated with a value calculated from all the bytes in the data area.
ii)Sector Slipping
Sector Sparing:
The controller can be told to replace each bad sector logically with one of the spare sectors. This scheme is known as sector sparing or forwarding.
Sector Slipping:
As an alternative to sector sparing, some controllers can be instructed to replace a bad block by sector slipping. (Also refer page no. 501 last para).
Bit Level Striping:
Data striping consists of splitting the bits of each byte across multiple disks.
Block-Level Striping:
In block level striping blocks of a file are striped across multiple disks.
A buffer is a memory area that stores data while they are transferred between two devices or between a device and an application. Buffer may hold only existing copy of a data item. This is known as Buffering. Buffering is done for three reasons.
Catching:
Cache holds a copy on faster storage of an item that resides elsewhere. This is known as catching. Caching and buffering are distinct functions, but sometimes a region of memory can be used for both purposes.
A spool is buffer that holds output for a device, such as a printer, that cannot accept interleaved data streams.
Another aspect of the system-call interfaces to the choice between blocking I/O and non-blocking I/O. when an application issues a blocking system call, the execution of the application suspended. Most operating system use blocking system calls for the application interface, because blocking application code is easier to understand than non blocking application code. Some user-level processes need non-blocking I/O. An example for non blocking I/O is a user interface that receives keyboard and mouse input while processing and displaying data on the screen.
The host is busy-waiting or polling: it is in a loop, reading the status register over and over until the busy bit becomes clear.
16 Mark Questions
(i)LOOK (ii)C-LOOK
(i)FCFS (ii)SSTF (iii)SCAN (iv)CLOOK
Source: https://www.snscourseware.org/snsct/files/CW_588c6a337842c/CS203-Operating%20System.doc
Web site to visit: https://www.snscourseware.org
Author of the text: indicated on the source document of the above text
If you are the author of the text above and you not agree to share your knowledge for teaching, research, scholarship (for fair use as indicated in the United States copyrigh low) please send us an e-mail and we will remove your text quickly. Fair use is a limitation and exception to the exclusive right granted by copyright law to the author of a creative work. In United States copyright law, fair use is a doctrine that permits limited use of copyrighted material without acquiring permission from the rights holders. Examples of fair use include commentary, search engines, criticism, news reporting, research, teaching, library archiving and scholarship. It provides for the legal, unlicensed citation or incorporation of copyrighted material in another author's work under a four-factor balancing test. (source: http://en.wikipedia.org/wiki/Fair_use)
The information of medicine and health contained in the site are of a general nature and purpose which is purely informative and for this reason may not replace in any case, the council of a doctor or a qualified entity legally to the profession.
The texts are the property of their respective authors and we thank them for giving us the opportunity to share for free to students, teachers and users of the Web their texts will used only for illustrative educational and scientific purposes only.
All the information in our site are given for nonprofit educational purposes